大模型是AI引擎,提示词工程即精准控制术…
一、 LLM(大模型)
1.国内外主要模型
国外主要模型:
- GPT系列:
ChatGPT (GPT-3.5系列)于2022年底上线,在两个月内用户破亿。它采用RLHF (人类反馈强化学习),更擅长对话生成。GPT-4于2023年发布,支持多模态输入,逻辑推理能力显著提升。GPT-4o于2024年5月推出,是支持文本/语音/图像输入的多模态版本,速度是GPT-4的两倍但成本更低。
- Anthropic的Claude: 2021年推出,强调安全与可靠性。最新的Claude 3系列在高级推理和编程任务上达到新标准,并广泛用于对话、编码、写作等场景。
- Google的Gemini (前Bard): 2023年推出,擅长搜索与对话。
- Meta的LLaMA系列: Meta发布的开源大模型,用于研究与商业集成。
国内主要模型:
- 百度的“文心一言” (ERNIE Bot): 擅长中文自然语言理解和生成,被媒体称为中国版ChatGPT,支持智能问答、内容创作、翻译等。
- 阿里的“通义千问” (Qwen): 自主研发的通用大模型,支持文本、图像、音频和视频等多模态输入。可进行文本创作、摘要、翻译、对话模拟等。
- DeepSeek 大模型:推出了多个开源大语言模型(如 DeepSeek-VL、DeepSeek-Coder、DeepSeek-MoE 等),具备较强的中文和英文处理能力,特别在代码生成和多模态推理方面表现优异。
- DeepSeek-VL 支持图文多模态输入
- DeepSeek-Coder 专注于代码生成与解释,已被广泛用于开源社区和企业开发中
1.1【ChatGPT】常见的自定义GPT有哪些?
- LangGPT 提示词专家✍️(langgpt.ai)
- Coding Code 👉🏼 Python Javascript React PHP SQL+(Widenex)
- [R2D2] Vue3 GPT(community builder):多语言支持的 Vue3 帮手。
- Node Mentor(Luis González):全栈 Node.js 专家。精通 Node.js、Express、Koa 等框架,并兼顾前端技术(CSS、Tailwind、Vue、React)。
- GoGPT (jobautomation.ai):Go 语言专家助手。提供 Go 语言的最佳实践、代码示例和坑点解析(如协程、通道用法、上下文取消等问题)。
- 全能程序员(zhibai.online):经验丰富的程序员和架构导师。擅长多种编程语言与架构设计,能给出项目分层、技术选型、目录结构等建议。
- DevOps GPT (Widenex):云运维专家。精通 Bash、AWS、Terraform、Kubernetes、Docker、Jenkins 等,多次强调“编写完整 CI/CD 管道”、“设计最佳架构”等能力。
2.LLM工作原理简介
大语言模型(Large Language Model, LLM)是一类经过海量文本数据训练的深度神经网络模型,具备理解和生成自然语言的能力。如:当前主流的LLM(如GPT 系列)基于 Transformer 架构,擅长处理序列数据,尤其适用于语言任务。
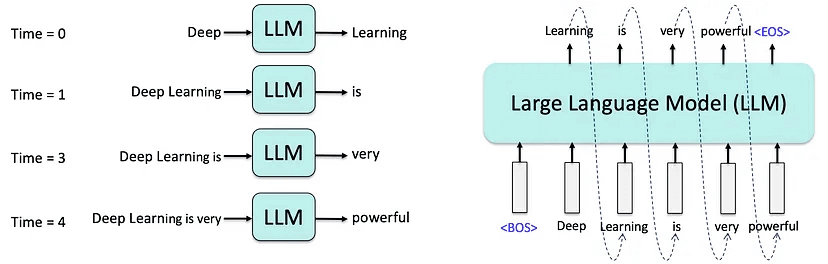
用一句话总结:通过对【上下文理解】和一定的【概率生成】, 【预测下一个词】。
注意:
- 上下文理解:上下文并非是一个词或一句话,而是模型捕捉上下文窗口中的一系列文本内容,作为【上下文语义和逻辑关系】。
- 上下文窗口(
Context Window):表示模型在一次处理过程中能“记住”的最大输入长度。举例:GPT-4 Turbo 支持的窗口长度为128k token(相当于几本小说的长度),超出窗口的内容将被截断或忽略,需合理控制输入量。
- 上下文窗口(
- 概率生成:模型会为所有可能生成的词分配概率(不同温度设置
temperature会影响输出的随机性与创造性),并选择最合理的那个。
对工程师的意义:模型不会主动思考。工程师作为”协作者“,负责通过【提示词】去“设定目标 + 编写指令”,控制模型的行为。
二、提示词工程(Prompt)
1.什么是提示词工程?
提示词工程(Prompt Engineering)是指通过精心设计输入给大语言模型(LLM)的指令(Prompt),以引导其输出更准确、相关和结构化的结果。
Prompt的目标:是与模型高效交互
- 精准控制模型行为 :明确指令去减少“猜意图”的不确定性。
- 提高输出质量,提升开发效率:在代码生成、文档编写、调试辅助等场景中节省时间。
- 增强一致性:确保不同请求下输出风格和格式统一,便于集成使用。
适用场景:
- 自动生成函数或类代码(如:“用typescript写一个快速排序算法,并添加类型注解”)
- 编写技术文档(如:“为用户登录接口生成API说明文档,包含参数、返回值和示例”)
- 数据分析脚本(如:“写一个nodejs脚本,读取CSV并统计各城市的订单总数”)
- 单元测试生成(如:“为该组件生成5个e2e测试用例,使用playwright框架”)
2.提示词的设计技巧和案例
2.1 设计技巧和案例
提示词通常由以下四个部分构成,根据任务灵活组合:
| 组成部分 | 作用 | 示例 |
|---|---|---|
| 指令(Instruction)清晰、具体 | 1-清晰:明确任务目标;2-具体:精确描述格式/要求/边界 | 用 Python 写一个函数,判断一个数是否为质数。 |
| 上下文(Context)丰富 | 提供必要背景信息和和角色信息,增强理解 | 说明开发目标、使用环境、你是谁、模型扮演谁 |
| 示例(Examples) | 展示任务模式,增强理解 | 输入:2 → 输出:True;输入:4 → 输出:False |
| 输出格式(Output Format) | 规定结果的形式或结构 | 结果请用JSON格式输出:{“is_prime”: true} |
高级提示技巧详解:
- 思维链提示(Chain-of-Thought, CoT)
- 用途:处理涉及多步推理、逻辑计算、流程拆解的任务。
- 策略:引导模型“逐步分析”而不是“一步到位”。
- 角色扮演提示(Role-playing)
- 用途:增强输出的专业性或风格一致性。
- 策略:明确模型的“身份角色”和任务背景。
- 链式提示词(Prompt Chaining)
- 用途:处理复杂任务(如代码生成 + 解释 + 测试)
- 策略:将大任务拆成小步骤,逐一引导。(支持条件分支、循环调用)
2.2 案例和优化策略
常见案例:
| 类型 | 特点 | 示例应用场景 |
|---|---|---|
| 零样本(Zero-shot) | 不提供示例,靠语言常识 | 直接提问、基础代码生成 |
| 少样本(Few-shot) | 提供1~3个示例,增强理解 | 数据转化、格式学习 |
| 思维链(CoT) | 要求模型逐步思考 | 数学推理、逻辑判断、流程拆解 |
3. 提示词评估和优化
3.1 评估和调试
从三大维度,评估模型输出效果:
| 维度 | 说明 | 示例判断方式 |
|---|---|---|
| 准确性(Accuracy) | 回答是否正确、符合事实或逻辑 | 生成的SQL语句是否能正确运行? |
| 相关性(Relevance) | 输出是否紧扣任务、避免偏题 | 是否回应了指令的关键需求? |
| 一致性(Consistency) | 结构、风格、格式是否稳定统一 | 输出是否前后一致、符合规范格式? |
调试提示词的技巧
- 1 - 分析输出找症结
- 输出错在哪里?(语法、逻辑、风格)
- 是否缺乏上下文、边界条件不清?
- 模型是否误解了指令、示例或角色?
- 2 - 逐一调整并观察
可调项 调整建议 指令 更明确任务目标,去掉模糊表达 上下文 增加背景、角色、目标说明 示例 更贴近实际输入输出结构 输出格式 明确要求结构、格式、长度限制等
小步调整,每次只改一个要素,便于定位问题
3.2 提示词常见问题与优化策略
常见问题
| 问题类型 | 现象 | 优化建议 |
|---|---|---|
| 忽略指令 | 模型答非所问、不按格式输出 | 重写指令更简洁具体,加“仅返回…”限定 |
| 内容冗长 | 出现大量背景解释、重复内容 | 加上“不要解释”、“仅输出核心代码”等限制语 |
| 偏离主题 | 输出包含无关信息或无效片段 | 提供更清晰的上下文/角色/输入边界 |
优化策略:借助大模型能力
A/B版【提示词一致性测试】(Cross-Model Prompt Testing):
- 用相同的输入样例分别调用模型,测试不同版本的提示词。
- 设置维度(如准确性、相关性、一致性 )对比输出差异,进行人工评估或基于业务指标(如正确率、运行成功率)打分持续迭代
【提示词评审员】:选择更强的模型(如 GPT-4 或 Claude 4)对你的提示词进行评估和改进建议
你是一个提示词专家,请分析下面这个提示词的问题,并给出优化建议: 原始提示词: "总结一下这篇文章的主要观点" 要求: - 是否清晰? - 是否有歧义? - 是否需要提供更多上下文? - 是否适合多种模型理解? 请给出修改后的版本
参考
- Caulde提示词分析: https://langgptai.feishu.cn/wiki/IS0pwsS96iWfE4kr3Bsc1ptvnpe
- Prompt Engineering Guide: https://www.promptingguide.ai/techniques/react
最后, 希望大家早日实现:成为编程高手的伟大梦想!
欢迎交流~

本文版权归原作者曜灵所有!未经允许,严禁转载!对非法转载者, 原作者保留采用法律手段追究的权利!
若需转载,请联系微信公众号:连先生有猫病,可获取作者联系方式!